
Falar sobre as fraudes online é chover no molhado, mas os dados são alarmantes: os golpes digitais aumentaram 35% no Brasil no ano passado. Sim, mesmo com os grandes esforços das empresas para proteger o ecossistema e as orientações dadas aos consumidores, as fraudes seguem crescendo.
Para se ter uma ideia, um recorte mais curto, entre julho e outubro de 2023 (antes da Black Friday), o Brasil registrou 623 mil tentativas de fraude que resultaram em perdas financeiras na casa dos R$ 748 milhões.
Realmente é assustador pensar no valor das perdas. O pior é que não é apenas por aqui que as fraudes seguem escalando. Nos Estados Unidos, mais de US$ 12,5 bilhões foram perdidos no ano passado com fraudes online, segundo um relatório do FBI.
O fato é que o comportamento das pessoas mudou com o avanço da tecnologia e as facilidades trazidas pelos dispositivos móveis. A pesquisa “E-commerce Trends 2024” revelou que 62% dos consumidores fazem de duas a cinco compras online por mês, enquanto 85% realizam pelo menos uma compra na internet mensalmente. Além disso, um levantamento da YouGov mostrou que 55,1% dos brasileiros preferem comprar produtos online do que nas lojas físicas.
Tamanha movimentação online atrai os fraudadores, que se aproveitam da demanda para tentar passar despercebidos pelos sistemas antifraudes. Para isso, os golpes são cada vez mais difíceis de serem identificados.
Isso significa que empresas que confiam apenas em análises primárias baseadas apenas no cruzamento de dados cadastrais estão longe de ficarem protegidas.
Com essas informações, vejo como inevitável a pergunta: “Como então manter o comércio eletrônico protegido?”. A resposta também está no avanço da tecnologia.
Machine learning no combate à fraude
Você já deve ter ouvido falar que vivemos uma era de dados. Realmente, nunca tivemos tantas informações disponíveis como agora para poder fazer uma avaliação. Ao mesmo tempo, a Inteligência Artificial já evoluiu a tal ponto que está madura o suficiente para ser utilizada para diversos fins, como por exemplo, o combate à fraude.
Isso ocorre porque as máquinas, obviamente, têm uma capacidade de analisar uma quantidade de dados infinitamente superior à dos humanos. Pense, por exemplo, em uma transação realizada em um marketplace. Uma análise manual pode olhar para variáveis como o local de onde a compra está sendo realizada, se o cartão de crédito já gerou chargeback ou se o CPF está ligado a alguma fraude. Porém, por mais competente que um analista de risco seja, é impossível analisar todas as variáveis manualmente com a agilidade que o ecommerce exige.
Um modelo preditivo baseado em machine learning (aprendizado de máquina) é capaz de processar um grande volume histórico de transações e utilizar técnicas estatísticas que irão encontrar padrões e cruzamentos que dificilmente seriam percebidos por uma pessoa. Com base nesse histórico, o modelo “aprende” o que diferencia comportamentos normais dos fraudulentos e com isso é capaz de calcular uma probabilidade de risco para novas transações.
Como um modelo preditivo é criado?
Este é um assunto um pouco técnico, mas vou tentar simplificar para demonstrar como o aprendizado de máquina pode ser utilizado no combate à fraude. Primeiramente, é importante destacar que a criação de um modelo preditivo exige uma quantidade considerável de dados históricos corretamente classificados.
Damos o nome de feature às variáveis que servem para treinar um modelo para que ele seja capaz de identificar os padrões da fraude. Cada feature representa uma característica da transação, como por exemplo o valor, o endereço de entrega e a lista de produtos. Algoritmos de machine learning são alimentados com esses dados e, através de técnicas estatísticas, são capazes de detectar padrões e cruzamentos automaticamente, gerando o modelo preditivo.
Uma das técnicas mais conhecidas para criação de modelos preditivos é a “árvore de decisão binária”. Com base nos dados de treinamento, o algoritmo cria uma série de perguntas que melhor classifica a transação em fraude ou não. Se você já jogou “Cara a Cara”, talvez se lembre: “Qual é a pergunta que posso fazer que elimina a maior quantidade de hipóteses?”. O objetivo da árvore binária é um pouco diferente, mas a intenção (buscar as melhores perguntas) é bem parecida.
O resultado do algoritmo após o treinamento é um fluxograma que poderá ser usado para prever o risco novas transações:
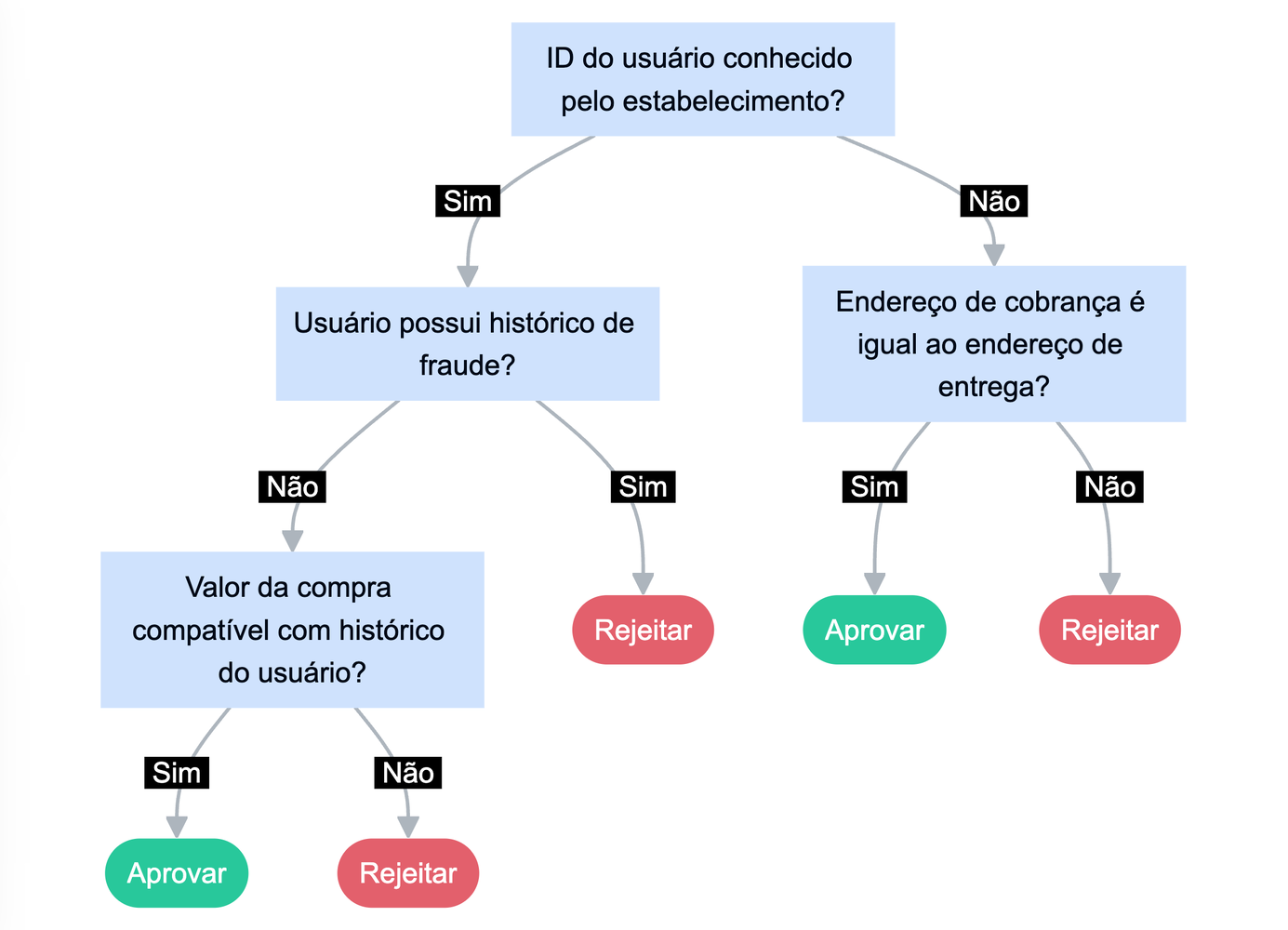
Claro que o exemplo acima é extremamente simples e contém poucas variáveis. O treinamento de um modelo real é capaz de processar milhares de features e analisar uma profundidade de correlações que seria inimaginável para um humano processar manualmente. Com isso, o resultado pode ser uma árvore com centenas ou milhares de perguntas que podem ser consultadas em poucos milissegundos.
Quais as vantagens do uso de machine learning no combate à fraude?
Escala operacional
Análises manuais podem ser úteis como última linha de defesa, porém é apenas através dos modelos preditivos que conseguimos escalar a operação de risco de forma sustentável com custos sob controle.
Agilidade na aprovação
Você sabia que a cada três pessoas que decidem fazer uma compra online, duas desistem por conta de uma experiência ruim na plataforma? A velocidade é uma das grandes vantagens de um modelo preditivo, já que ele muito mais rápido do que uma análise manual. Além de proteger as empresas, modelos preditivos ainda auxiliam a reduzir a fricção e aumentar a conversão de vendas.
Quais os desafios para manter modelos preditivos?
Modelos preditivos treinados adequadamente podem ajudar a reduzir a quantidade de fraudes que chega até um estabelecimento, porém, o principal desafio é mantê-los atualizados frente as novas ameaças. A boa notícia é que é possível atualizar esses dados constantemente, criando um “aprendizado contínuo” que estará sempre aperfeiçoando os modelos contra novas fraudes.
Na Glass Data, cada cliente possui seu próprio modelo preditivo, atualizado de forma automática, adaptado ao comportamento de cada estabelecimento.
Conclusão
Claro que não entrei em todos os detalhes técnicos, mas tentei trazer um pouco de luz sobre o uso de machine learning no combate à fraude.
Você tem alguma dúvida sobre a utilização de machine learning e modelos preditivos em seu negócio? Será um prazer esclarecer alguns pontos importantes e até mesmo prestar uma breve consultoria sobre o tema. Entre em contato com nosso time por meio deste link.